Processors
Processors are components that can transform, validate, or enrich messages and perform other processing tasks.
The Processors page is where you can view and add your processors.
On the Processors page, view the list of processors.
Search for a processor
On the Processors page, you can search for a specific processor using the default search fields.
In the top right corner of the page, select Create Processor.
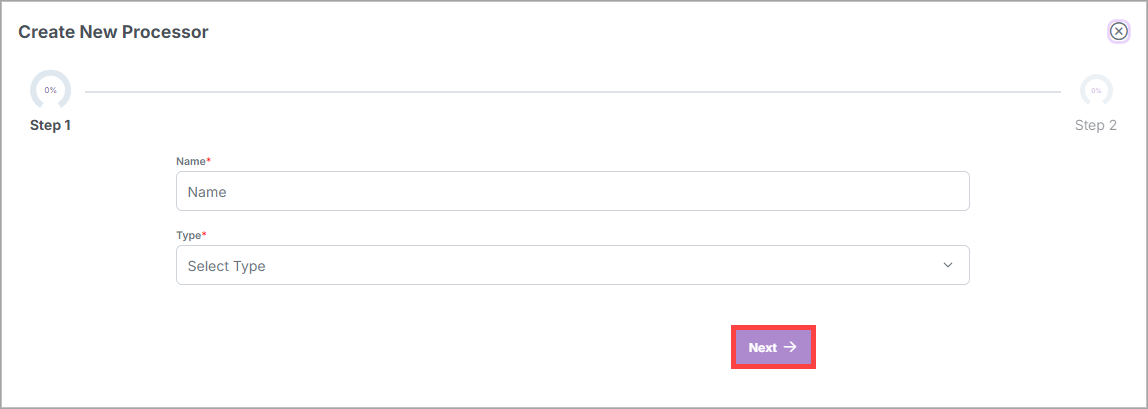
In the Create New Processor dialog box, enter the initial processor information, and select Next.
Note
For EDI FILE and VALIDATION processors, the Pattern option displays where you must specify a pattern such as consumer or producer.
Continue entering the additional processor information and then selecting Next until you reach the final step.
Select Create Processor. The Processor Details page displays as a draft version of the processor.
In the top right corner of the page, select Approve > Yes to approve the draft.
If the Peer Review feature is enabled in General Settings, the processor must be approved by a peer with the Manager role or higher before it can be activated.
The processor has the name you gave it and an ID that X1 automatically assigned to it, based on the name.
The ID is lowercase and replaces spaces with dashes, and it's also permanent and can't be edited.
Note
If you want to delete the draft before approving it, select
 .
.
Note
The processor has the name you gave it and an ID that X1 automatically assigned to it, based on the name. The ID is lowercase and replaces spaces with dashes.
The ID is permanent and can't be edited.
See the "New Processor Field Descriptions" below for more information about the processor fields.
New Processor Field Descriptions
Field | Section |
|---|---|
Name | Enter a relevant name for the processor. |
Type | The type of processor determines many of the unique configuration properties and behavior of the processor:
|
Note
After you create the processor, its details page displays where you can add additional information about the processor.
See the procedures below for more information about creating each type of processor.
Composed message processors are an enterprise integration pattern that splits a message on a configured key, processes each split message individually, and then aggregates the responses into a single message. This is useful when multiple properties of a message need to be processed individually, as is often the case in enrichment.
For example, an order document message may contain a list of items. If each item must be processed individually, you can use a composed message processor to split the message into individual items, process each item individually, and then aggregate the results into a single message.
The output of a composed message processor is always an X1 envelope that contains a list of objects as its document, where each object is the result of processing one of the split messages.
Refer to the table below for guidance after you've completed the initial steps in the Create a processor procedure above.
Field and tab | Description |
|---|---|
Name | The name you provided when you initially created the processor. |
Adapter | The name of the context that the processor runs in. |
Description | Enter a relevant description of the processor. |
Input Type | The document type the processor expects to receive. The type of document message that the processor receives from the external system. |
Output Type | The document type the processor will return. The type of document message that the processor returns to the external system. |
General tab | |
Split On | The property of the message to split on. This is the property of the message used to split the message into individual messages using a dot (.) delimited path. It defaults to body, which represents the message body. Example: body.items |
Parallel Processing | Select if you want the composed message processor to split and process messages in parallel. This dramatically speeds things up for big payloads. |
Processor Flow (Create Flow) | Select Create Flow to open the Flow Designer and display the flow of components to execute for each split message. |
Options tab | |
Log Message Headers | You can log the message headers of the message for any events that the processor logs. If yes, you can enter an optional "Include Headers" regular expression to specify which headers to include in the flow run event. All headers are logged if you don't provide the regular expression. NoteLogging message headers can be helpful in troubleshooting, but be aware that this can expose sensitive information in the flow run events. |
Custom Error Handler? | Optional: If yes, you can add custom error handling to determine how errors are handled for the processor. Select the type and name of the error handler. |
Flows tab | The flow of components used to process the split messages. This is the flow that will be used to process each of the split messages. |
EDI File consumer processors use the codes in the EDI File to determine which EDI spec to use to validate and map the message. This is determined for each transaction set in the EDI using the sender ID, transaction set code, and version.
An EDI File consumer processors processes EDI files using the following process:
Incoming files are parsed, and each transaction set is sent as it is parsed to be validated and mapped.
X1 looks up the EDI spec for the transaction set and validates it.
If the transaction set is valid, it's mapped to the canonical representation of the EDI message defined in the spec.
The canonical document is saved and routed to the next component in the flow.
Once all transaction sets in a group are processed, a group result is created with the results of the processing of the transaction sets.
EDI File producer processors handle outgoing EDI messages. They work by converting a message that is in the canonical representation expected by an EDI spec to the EDI format expected by the receiver.
A typical process for an EDI File producer processor is as follows:
Translate a message into the canonical representation expected by the EDI spec.
Send the message to the EDI File producer processor.
The processor looks up the EDI spec for the message and maps it to the EDI format expected by the receiver.
The EDI message is sent to the receiver.
Refer to the table below for guidance after you've completed the initial steps in the Create a processor procedure above.
Field and tab | Description |
|---|---|
Name | The name you provided when you initially created the processor. |
Adapter | The name of the context that the processor runs in. |
Description | Enter a relevant description of the processor. |
Input Type | The document type the processor expects to receive. The type of document message that the processor receives from the external system. |
Output Type | The document type the processor will return. The type of document message that the processor returns to the external system. |
General tab | |
Reject on error? | NoteThis option is available for EDI FILE producers only. Rejects the message if any of the EDI transaction sets are invalid. |
Remove any reserved characters? | NoteThis option is available for EDI FILE producers only. Automatically removes any reserved characters (element separator, segment terminator, composite separator) in the text of the EDI document during EDI generation that will make the EDI invalid. |
Send FA? | NoteThis option is available for EDI FILE consumers only. If yes, send an FA (Functional Acknowledgment) back to the sender.
When an EDI File Consumer Processor processes an EDI Group, it produces an EDI Group Result that can be sent to an Endpoint or Router. Whatever component ultimately sends the FA converts the EDI group result into a functional acknowledgment (FA). To send functional acknowledgment, enable the Send FA property on the EDI File Consumer Processor, select Router or Endpoint as the component type to send the functional acknowledgment to, and then select a component from the list of available components. The component must be an Endpoint or Router that accepts an EDI Group Result as its input type. |
Component Type | NoteThis option is available for EDI FILE consumers only. Select either Router or Endpoint. |
Acknowledgement Router | NoteThis option is available for EDI FILE consumers only. Select depending on the component type. |
Auto generate FA? | NoteThis option is available for EDI FILE consumers only. Automatically generate a functional acknowledgment. |
EDI Type | The EDI document standard: EDIFACT or ANSI X12. |
Options tab | |
Log Message Headers | You can log the message headers of the message for any events that the processor logs. If yes, you can enter an optional "Include Headers" regular expression to specify which headers to include in the flow run event. All headers are logged if you don't provide the regular expression. NoteLogging message headers can be helpful in troubleshooting, but be aware that this can expose sensitive information in the flow run events. |
Custom Error Handler? | Optional: If yes, you can add custom error handling to determine how errors are handled for the processor. Select the type and name of the error handler. |
Flows tab | The flow of components used to process the split messages. This is the flow that will be used to process each of the split messages. |
Enrichment processors work by sending a message to an endpoint to retrieve additional data. The response from the endpoint is then mapped to the message using a translator. This allows users to enrich messages with additional data from external systems.
Sometimes, the existing message being processed can be sent to the external endpoint or no message is sent at all, such as in the case of a GET request). However, a specific message must often be sent to the enrichment endpoint. This can be accomplished by specifying a request translator to translate a message to the format expected by the endpoint.
An example of an enrichment processor use case is if the document message being processed represents an order, and you must enrich each location with a time zone. To accomplish this, you create an endpoint that fetches the time zone from an external server and a translator to map the time zone response to the message. You then create a request translator to create a request appropriate for the enrichment endpoint. Finally, all these components are configured in an enrichment processor.
Refer to the table below for guidance after you've completed the initial steps in the Create a processor procedure above.
Field and tab | Description |
|---|---|
Name | The name you provided when you initially created the processor. |
Adapter | The name of the context that the processor runs in. |
Description | Enter a relevant description of the processor. |
Input Type | The document type the processor expects to receive. The type of document message that the processor receives from the external system. |
Output Type | The document type the processor will return. The type of document message that the processor returns to the external system. |
General tab | |
Request Translator | Optional: The translator used to translate the message to the format expected by the endpoint. |
Enrichment Endpoint | The endpoint to call to retrieve the additional data. This is the ID of the endpoint to call. |
Enrichment Translator | The translator to use to translate the response from the endpoint to the message. |
Payload tab | |
Split? | Optional: If yes, split the message before processing. A Split On property must be specified. |
Log Message Headers | You can log the message headers of the message for any events that the processor logs. If yes, you can enter an optional "Include Headers" regular expression to specify which headers to include in the flow run event. All headers are logged if you don't provide the regular expression. NoteLogging message headers can be helpful in troubleshooting, but be aware that this can expose sensitive information in the flow run events. |
Error Handling tab | |
Custom Error Handler? | Optional: If yes, you can add custom error handling to determine how errors are handled for the processor. Select the type and name of the error handler. |
Flows tab | The flow of components used to process the split messages. This is the flow that will be used to process each of the split messages. |
Refer to the table below for guidance after you've completed the initial steps in the Create a processor procedure above.
Note
Before you save a Validation processor, you can test it by selecting Test in the top right corner of the page.
The Test Result dialog box displays to inform you if the validation passed or failed.
Field and tab | Description |
|---|---|
Name | The name you provided when you initially created the processor. |
Adapter | The name of the context that the processor runs in. |
Description | Enter a relevant description of the processor. |
Input Type | The document type the processor expects to receive. The type of document message that the processor receives from the external system. |
Invalid Message? | Optional: If Error, an error will occur and be processed according to standard error handling or with a custom error handler if defined. If Dead Letter, the message is sent to the dead letter collection. NoteIn both cases, processing of the message stops. |
General tab | |
Add Processor Rule | You can create processor rules to validate messages. Each processor rule consists of a name and a Groovy script that specifies the condition and returns a Boolean value. If the script returns true, the processor rule passes. If the script returns false, the processor rule fails. Processor rule scripts are executed against the message body and have the body and headers variables available. The body variable contains the message body, and the headers variable contains the message headers. Normally, the body consists of an X1 envelope, which contains a document and a header. A good processor rule is small, specific, and easy to understand. Since the rules are written in Groovy script, it is good to take advantage of Groovy's expressive syntax. Here are some examples: Example 1: Validate that the height and weight exist for every line item in a list body.document.lineItems.every {
it.weight &&
it.weightUom &&
it.freightClass &&
it.quantity &&
it.length &&
it.width &&
it.height &&
it.lengthUom
}Example 2: Validate that the origin and destination are present body.document.with {
destZip &&
originZip &&
destCity &&
originCity
}Example 3: Validate that a specific stop has a scheduled date body.document.updatedShipment.stops
?.find { it.sequenceNumber == 1 }
?.scheduledAppointmentEarliest |
Options tab | |
Log Message Headers | You can log the message headers of the message for any events that the processor logs. If yes, you can enter an optional "Include Headers" regular expression to specify which headers to include in the flow run event. All headers are logged if you don't provide the regular expression. NoteLogging message headers can be helpful in troubleshooting, but be aware that this can expose sensitive information in the flow run events. |
Error Handling tab | |
Custom Error Handler? | Optional: If yes, you can add custom error handling to determine how errors are handled for the processor. Select the type and name of the error handler. |
Test Document tab | Optional: A JSON or string representation of a document used to test the validation rules to ensure they're working as expected. |
Flows tab | The flow of components used to process the split messages. This is the flow that will be used to process each of the split messages. |
In the top right corner of the page, select Import Processor. The Import Processor dialog box displays.
Drag and drop a document, or select Choose and browse to it.
Select Upload. The imported processor information is added to the Processors table.
In the Processors table, do one of the following:
Next to a processor, select
 . The Processor Details page displays the General tab by default.
. The Processor Details page displays the General tab by default.Select a processor's ID, Name, or Type. The Processor Details page displays the General tab by default.
In the top right corner of the page, select New Draft.
Note
If you want to delete the draft before saving it, select
.Edit the processor information.
In the top right corner of the page, select Save > Approve.
Note
When you select Save, your edits are saved as an unapproved draft.
At this point, you can leave the saved draft unapproved if you want to come back to it later to do more editing.
When you want to edit the component again, in the top right corner of the page, select Show Draft to access its unapproved draft.
When you select Approve, the unapproved draft is deployed as the current version.
In the top right corner of the page, you can select the drop-down arrow to revert to a previous version.
To the left of the drop-down list, you can select
 to view when the page was last modified.
to view when the page was last modified.
Next to a processor, select
 . The Confirm Export dialog box displays.
. The Confirm Export dialog box displays.Select Yes.
In the Processors table, do one of the following:
Next to a processor, select
. The Processor Details page displays the General tab by default.Select a processor's ID, Name, or Type. The Processor Details page displays the General tab by default.
In the top right corner of the page, select Restart. The Confirm Restart dialog box displays.
Select Yes.
Next to a processor, select
 . The Delete Processor dialog box displays.
. The Delete Processor dialog box displays.Select Delete.